HTTP服务器server架构分析—StateThreads示例程序介绍
作者:罗上文,微信:Loken1,公众号:FFmpeg弦外之音
HTTP服务器 server 程序 的主要流程如下:
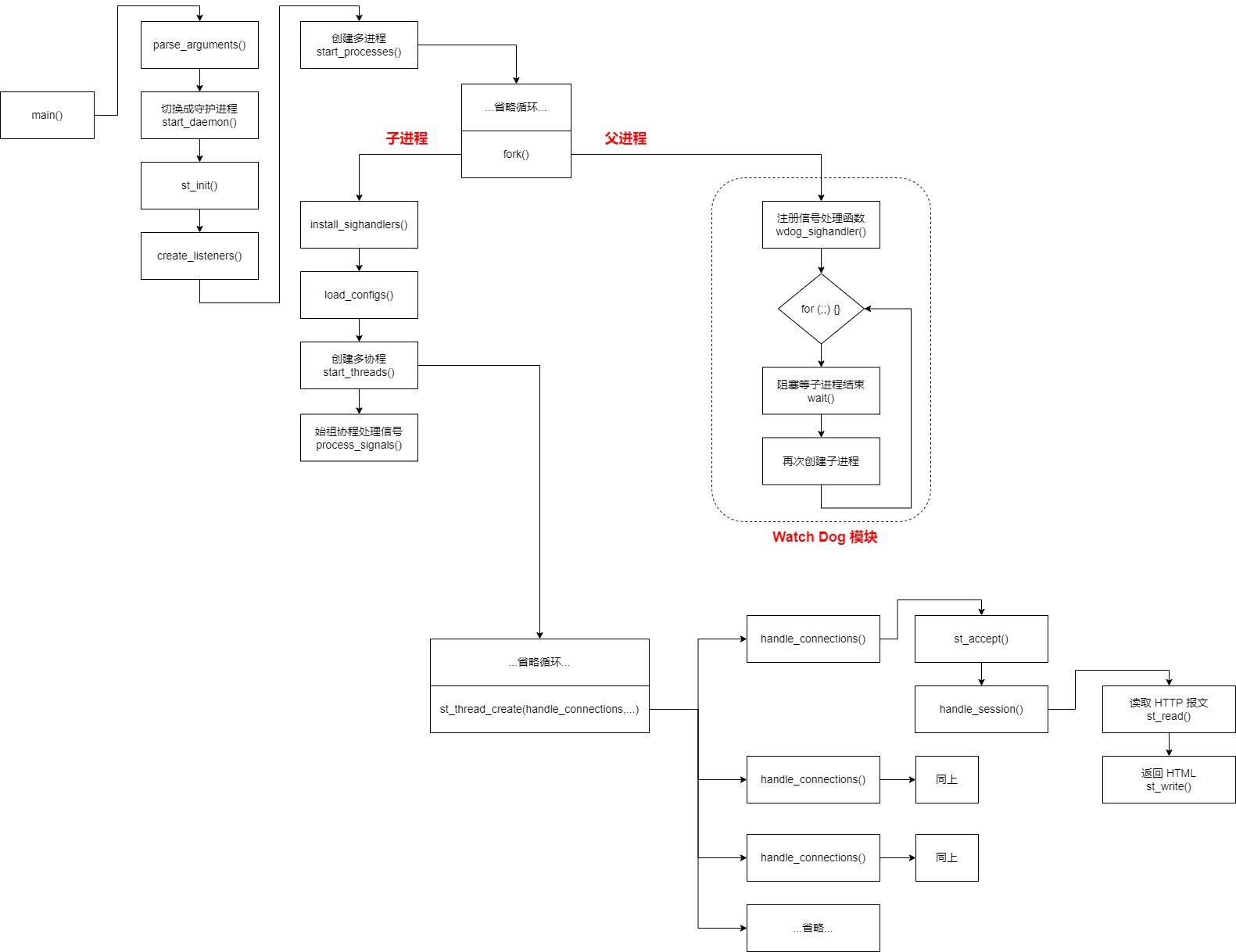
server 程序其实有多个模块的,如下:
1,create_listeners() 创建 listening sockets 列表
server 程序其实是可以监听多个 地址的,如下:
./server -l ./log -p 5 -b 192.168.0.109:8888 -b 127.0.0.1:1234
上面就监听了两个地址,所以 create_listeners() 函数内部会创建 2 个 listening sockets,这是存储在数组 srv_socket[] 里面的,sk_copunt 就是这个数组的长度,也就是 2。
监听 2 个地址 比 监听 1 个地址的协程数量多一倍,如下:
2,start_processes() 开启子进程处理 HTTP 请求
start_processes() 内部会开启多个子进程来处理 HTTP 请求,如下:

fork() 函数的逻辑是有点复杂的,fork() 其实会产生一个新的逻辑分支。你可以理解 fork() 返回了两次,当返回值 pid 等于 0 ,代表这是子进程的逻辑分支。当 返回值 pid 大于 0,代表这是原来 父进程的逻辑分支,pid 就是 子进程的进程ID。
当 -p 等于 5 的时候,父进程的逻辑分支一直在 for 循环里面循环了 5 次,而 创建出来的子进程 立即就退出了 start_process() 函数了,子进程会跑到 install_sighandlers() 的流水线继续去执行。
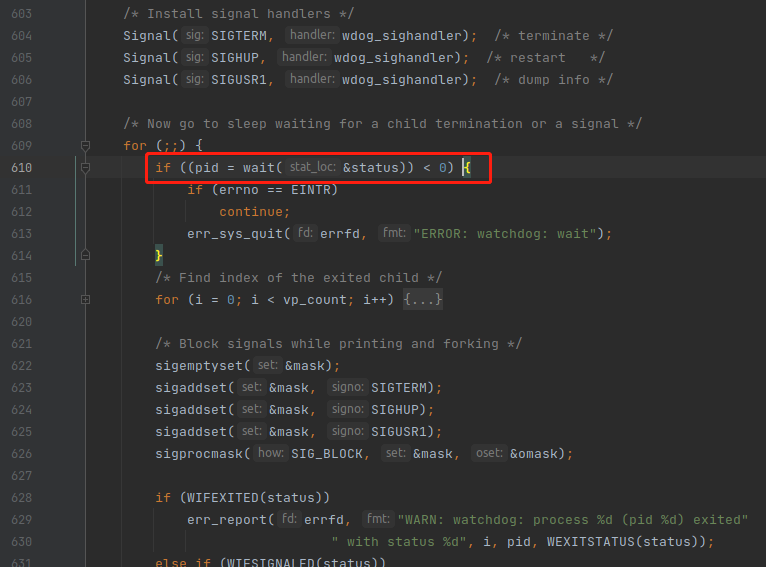
当父进程 循环完 for(), 开启完 5 个子进程去处理 HTTP 请求之后,父级进程自己会变成一个 Watch Dog 进程,负责监控各个子进程的运作状态。
他使用的是 wait() 函数,这个函数一开始会阻塞,一直等到有子进程退出,wait() 就会返回退出的子进程的进程ID 以及 退出状态。而 父进程 看到有子进程退出了,就会重新创建一个子进程来处理 HTTP 请求。
我的服务器开了 5 个 server 的 HTTP 进程,现在我把其中一个 26883 进程 kill 掉。会发现,会再有一个新的进程 26701 重新创建处理,如下:
kill -9 26683
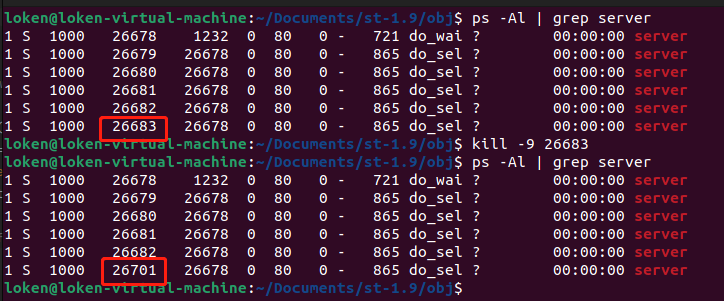
这就是父级进程的 Watch Dog 功能。在 Linux 环境,有一个软件也可以实现这种 看门人 功能,就是 supervisor。
3,start_threads() 开启多协程处理 HTTP 请求
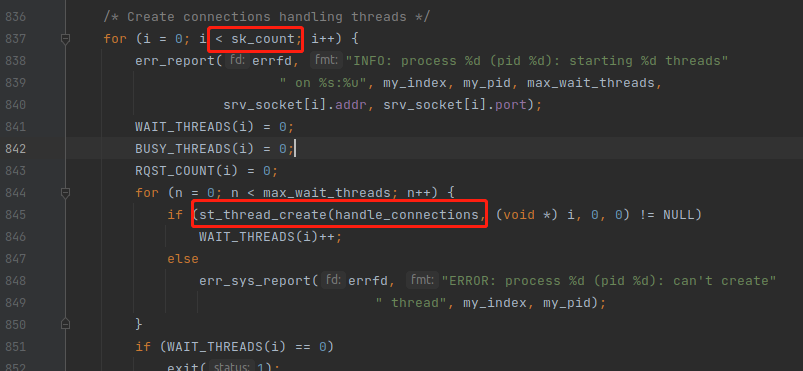
start_threads() 其实已经处于 子进程的流水线,start_threads() 内部会创建多个 handle_connections() 协程,全部阻塞在 st_accept() 里面等待浏览器的 HTTP 请求。
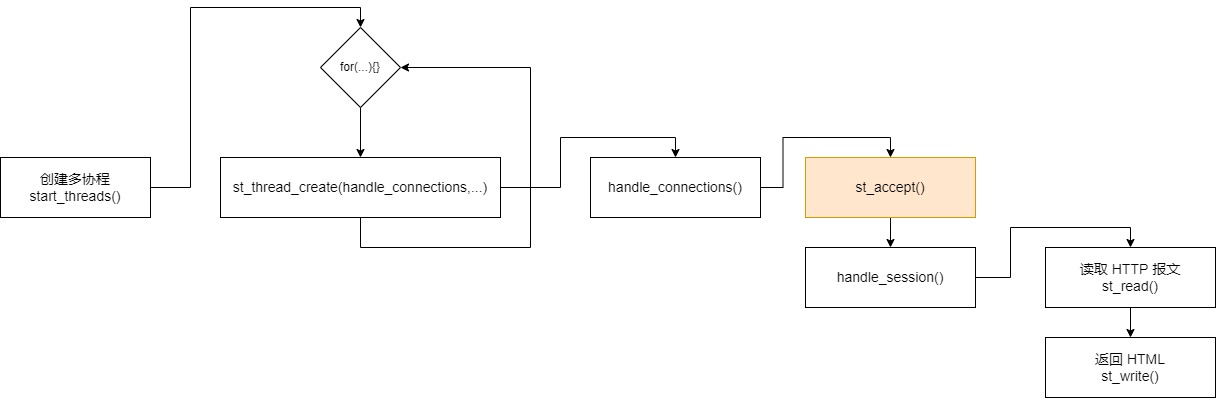
上图是单进程的流程,一个进程里面多个 handle_connections() 协程,内部全部都是 st_accept() 同一个 listening socket 的,当浏览器请求来的时候,只有一个 handle_connections() 协程被激活,然后去处理请求。
这里剧透一下 st_accept() 函数的一些内部原理,虽然是多个 协程全部 st_accept() 同一个 socket,但是其实内部只有一次 select/epoll_wait 调用。因为多个协程是共用一个 全局的 Socket 集合 的。
select/epoll_wait 的调用如下:
// event.c 第 331 行
nfd = select(_ST_SELECT_MAX_OSFD + 1, rp, wp, ep, tvp);
// event.c 第 1268 行
nfd = epoll_wait(_st_epoll_data->epfd, _st_epoll_data->evtlist, _st_epoll_data->evtlist_size, timeout);
当 select/epoll_wait 被激活的时候,就会选取最先执行 st_accept() 的那个协程来处理这次的请求。
上面单进程的情况,但是 server 程序本身是有 多个进程的,前面的 create_listeners() 创建 listening sockets ,然后再执行 fork() 创建子进程的,进程本身是内存隔离的,所以 fork() 会复制多块父级进程的内存。fork() 的内存复制是写时复制。
但是 select/epoll_wait 系统调用 本身是支持多进程同时 select/epoll_wait 同一个 listening sockets 的,也是只会激活其中一个进程来处理这个请求。
整体的逻辑就是 5 个 server 进程同时 select() 监听同一个 listening sockets,当浏览器请求来的时候,就激活其中一个进程来处理,假设是进程 26683。
然后进程 26883 会激活最先执行 st_accept() 的那个协程来处理这次的请求
4,max_threads 控制协程数量
server 会通过 max_threads, max_wait_threads,min_wait_threads 控制每一个 listening socket 的协程数量,以下面的命令为例。
./server -l ./log -t 20:50 -p 5 -b 192.168.0.109:8888 -b 127.0.0.1:1234
上面监听了两个地址,所有会有两个 listening socket,这时候 sk_count 等于 2 ,srv_socket[] 数组的长度就是 2
同时使用了 -t 选项,-t 是用来指定 max_wait_threads 与 max_threads 的。上面的命令,我设置了 max_wait_threads 等于 20,max_threads 等于 50。
max_threads 不是指单个进程里面的最大协程,而是指所有进程加起来的最大协程,所以上面是每个进程最多开 10 个协程。
max_wait_threads 也是指所有进程的最大空闲协程的数量,所以上面每个进程最多有 4 个协程是空闲的。
控制协程数量的策略有点复杂的,如下:
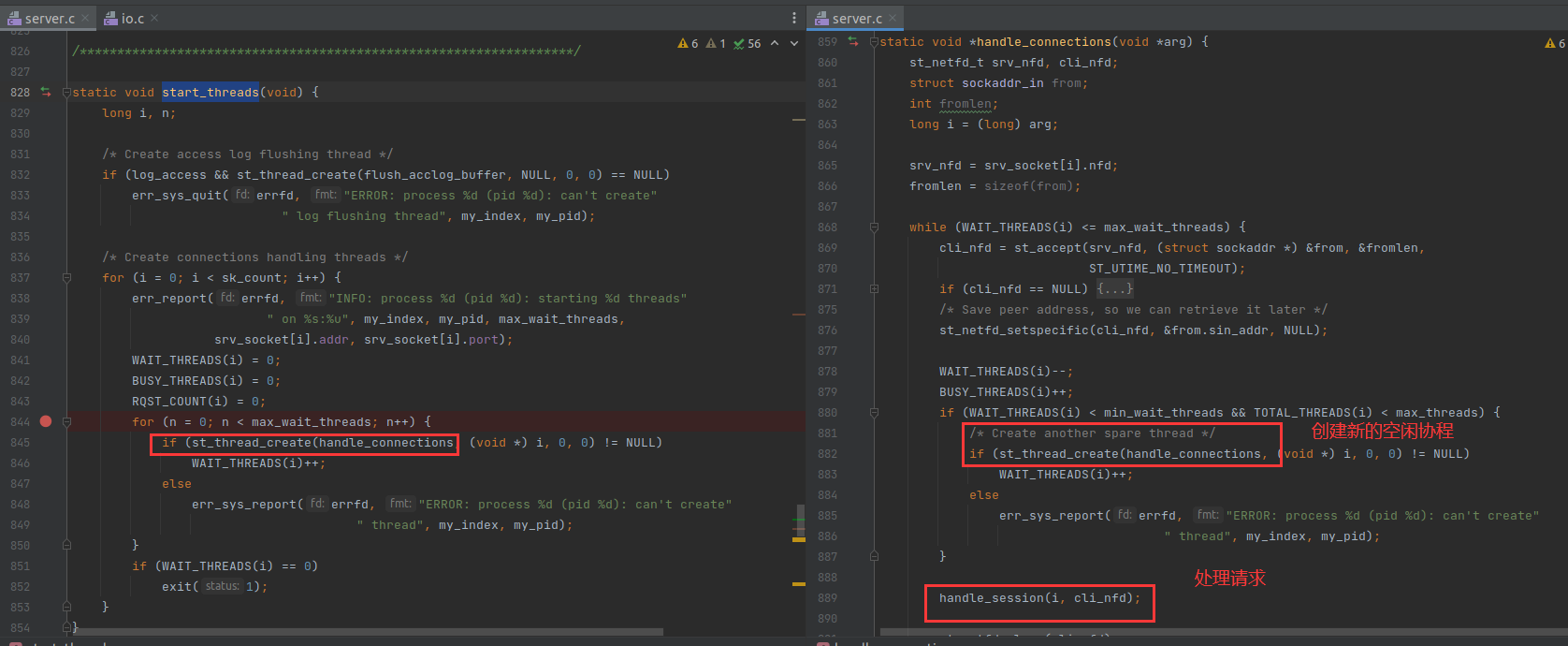
上面这段代码的意思是,当 start_threads() 函数执行完之后 ,就会有创建 4 个空闲协程出来阻塞在 st_accept() 里。这时候一个进程里面就有 4 个协程,而且全部都是空闲的。假设这些协程的编号位 1 2 3 4
然后当浏览器发送一个 HTTP 请求来的时候,协程 1 就会激活,协程 1 负责调 handle_session() 处理这个 HTTP 请求。但是在此之前,协程1 会再次创建一个 空闲协程5 来处理,协程5 会阻塞在 st_accept() 负责接受新的请求。
此刻 协程1 不是空闲协程了,而是在忙碌处理 HTTP 请求。空闲协程是 2~5。所以,他的策略是尽量保证有 4 个空闲协程在等待 HTTP 请求到来。
再假设另一个例子,浏览器一下子发送 4 个 HTTP 请求,那协程 1~4 都会变成 busy 协程,但是也会重新创建 5~8 的空闲协程处理,所以此刻总协程数量 TOTAL_THREADS 就是 8 个协程。
TOTAL_THREADS 不是无限的,当达到 我们前面设置的 10 个的时候,就不会再创建空闲协程。
所以,如果浏览器一下子发送 12 个 HTTP 请求,假设只有一个 server 进程,max_threads 等于 10,那 10 个协程都会变成 busy,空闲协程的数量是 0 个。
而且最后两个 HTTP 请求要后面才能处理。这就是 server 程序的协程数量控制策略。
上面我们用 -t 选项指定了 max_wait_threads 与 max_threads ,这样其实不是太好。通常我们不需要使用 -t ,让他根据服务器的性能自动选择合适的协程数量即可。
他默认的协程数量策略如下:
if (max_wait_threads == 0)
max_wait_threads = MAX_WAIT_THREADS_DEFAULT * vp_count;
/* Assuming that each client session needs FD_PER_THREAD file descriptors */
if (max_threads == 0)
max_threads = (st_getfdlimit() * vp_count) / FD_PER_THREAD / sk_count;
MAX_WAIT_THREADS_DEFAULT 等于 0 ,所以他默认是每个进程里面最多有 8 个空闲协程。
st_getfdlimit() 获取的是事件驱动能支持的最大 socket fd,select() 函数支持的是 1024 个 fd。而 FD_PER_THREAD 等于 2,就是每个协程负责处理 2 个请求。vp_count 是 server 进程的数量,sk_count 是监听地址的数量
所以每个进程默认最多开 1280 个协程,如下:
max_threads = (1024 * 5) / 2 / 2 = 1280
