SRS的线程池介绍SrsThreadPool—SRS源码分析
作者:罗上文,微信:Loken1,公众号:FFmpeg弦外之音
SRS 里面跟线程池相关的数据结构是 SrsThreadPool、SrsThreadEntry,他们的关系如下:
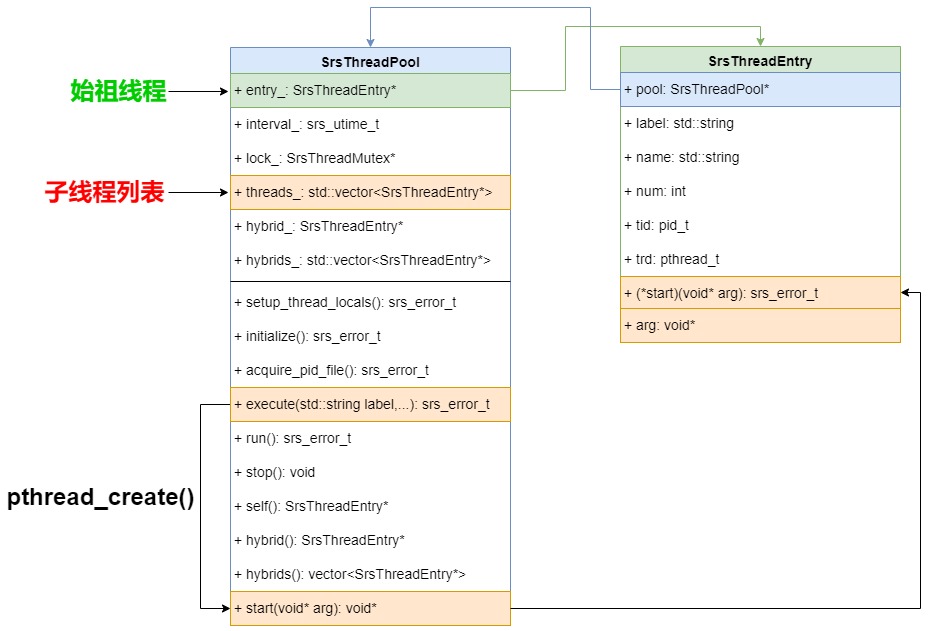
刚开始看这个这个结构的时候,我以为 SRS 的线程池的设计是,预先创建一堆线程,然后把任务丢进去,根据任务的数量或者相关的情况去自动消耗线程,
但后来我发现,SRS 的线程池设计并没有那么复杂,他很简单的。SrsThreadEntry 类就是单个线程的信息,它的 start() 函数就是执行的具体的任务。而 SrsThreadPool 类可以理解为线程的管理器,SrsThreadPool::threads_ 字段是一个 vector 数组,负责管理所有的线程。
SrsThreadPool 类的 execute 函数就负责创建一个 新的线程实例 SrsThreadEntry ,run() 函数负责定时监控所有线程的状态。
下面我们来仔细讲一下 SrsThreadPool、SrsThreadEntry 这两个类里面的各个字段跟方法。
SrsThreadPool 类
SrsThreadPool 类的字段如下:
1,SrsThreadEntry* entry_
entry_ 存储的是始祖线程的信息,也就是 main 线程自己。
2,srs_utime_t interval_
interval_ 是间隔的意思吧?xxx,后面补充。
3,SrsThreadMutex* lock_
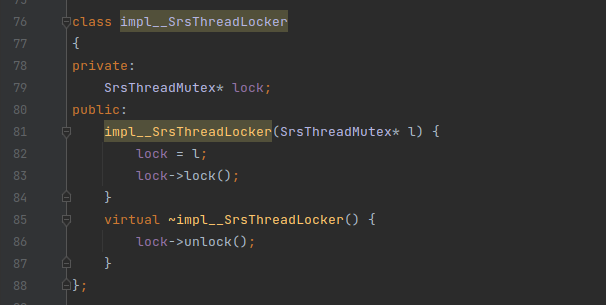
这个字段是配合 SrsThreadLocker() 函数用的, SrsThreadLocker() 是一个宏函数,他实际上就是创建一个 锁 对象实例,SrsThreadLocker() 的定义如下:
#define SrsThreadLocker(instance) \
impl__SrsThreadLocker _SRS_free_##instance(instance)
SrsThreadLocker(lock_);
展开之后如下
impl__SrsThreadLocker _SRS_free_lock_(lock_)
实际上就是创建了一个 _SRS_free_lock_ 变量,而这个变量的类型是 impl__SrsThreadLocker,impl__SrsThreadLocker 类的构造函数就是加锁,而析构函数就是释放锁。如下:
4,std::vector<SrsThreadEntry*> threads_
threads_ 是线程列表,execute() 创建的线程 都会加进去 线程列表,方便管理。
5,SrsThreadEntry* hybrid_
hybrid_ 存储的是 混合线程 的信息,由于 SRS 的线程化还没有完成,所以他并不是每个模块里面开一个线程或者多个线程,例如 RTSP 一个线程,RTMP 一个线程,或者 WebRTC 开多个线程。他暂时还不是这样的。他是所有的模块都混在 hybrid_ 线程里面,目前还没完成线程化。但是线程池设计已经做好了的,我觉得线程池的设计后面改动应该不会太大。
所以 hybrid_ 顾名思义就是混合线程的意思,在 execute() 创建的线程,如果 label 是 hybird,
6,int pid_fd
进程ID 的文件描述符,注意,这个不是进程 ID,是一个文件的描述符,这个文件的内容就是进程的ID。
SrsThreadPool 类的方法如下:
1,static srs_error_t setup_thread_locals()
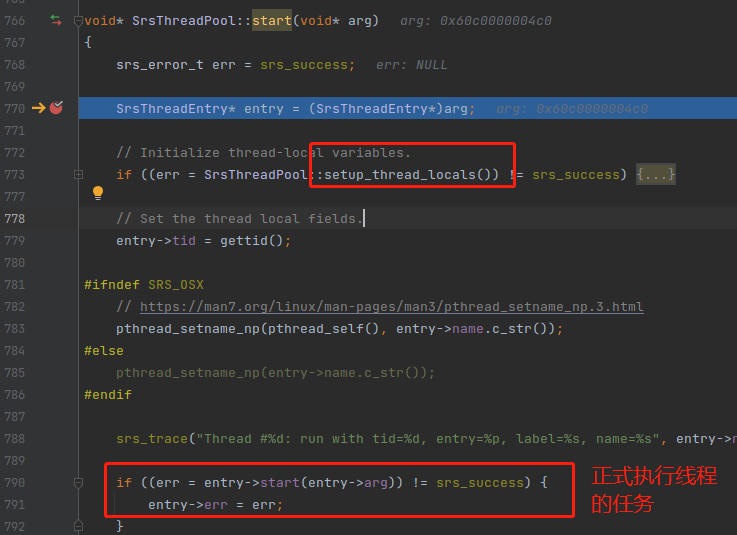
setup_thread_locals() 里面就是调了一下 srs_st_init(),这个是 StateThreads 协程库的初始化函数。里面是对一些全局变量做初始化,由于 SRS 的多线程改造,已经把这些全局变量变成 thread local 模式了,所以在每次执行新的线程任务之前,都要调一下 setup_thread_locals(),如下:
2,srs_error_t initialize()
initialize() 函数非常简单,就是调 acquire_pid_file() 获取一个进程 ID,保存进去文件。还有获取配置文件的 interval_,interval_ 是干什么的后面补充一下。
3,virtual srs_error_t acquire_pid_file()
acquire_pid_file() 的作用就是获取进程ID,保存进去文件。然后把文件描述符赋值给 SrsThreadPool::pid_fd 字段。
4,srs_error_t execute(std::string label,...)
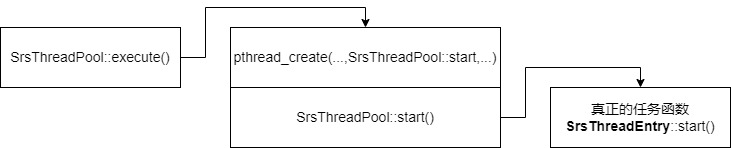
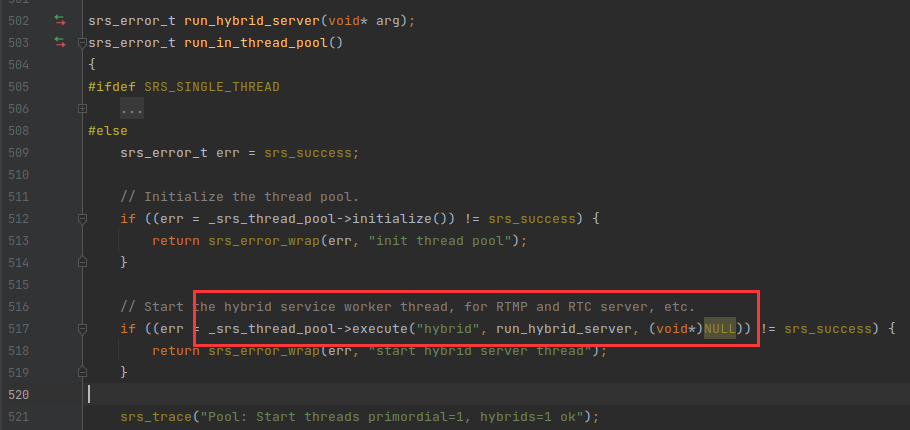
execute() 函数是负责创建线程来执行任务的,他会先开线程运行 SrsThreadPool::start() 函数,然后再 start() 里面才真正运行 SrsThreadEntry 里的任务函数。流程 如下:
5,srs_error_t run();
run() 函数负责运行 始祖线程,始祖线程 的作用就是检测其他线程的运行状态,类似 watch dog,如下:
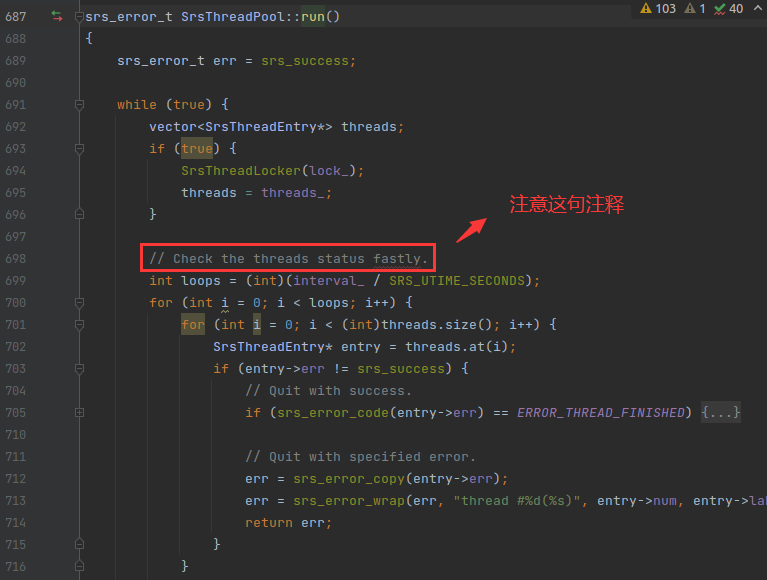
他的检测算法 还有 interval_ 变量比较难懂,上面的代码 for 循环里面有两个 i,逻辑看起来比较绕。不知道是写错了?还是故意设计出两个 i 的?
补充:是写错了,是个 bug。应该是 int i 与 int j
SrsThreadEntry 类
SrsThreadEntry 类的字段如下:
1,SrsThreadPool* pool
你可以把 SrsThreadEntry 理解为一个线程实例,而 pool 负责把 线程实例 绑定到具体的线程池里面。
2,std::string label
label 是线程的标签,目前只有两个标签,primordial 与 hybrid,其实我个人觉得这个 label 应该用枚举类型来实现更好一些。
3,std::string name
name 是线程的名称,他还用了 pthread_setname_np() 来把这个 name 设置成线程的名称,所以你在调试器里面是可以直接看到这个 名称,这样可以在调试的时候非常容易的区分各个线程。
#ifndef SRS_OSX
// https://man7.org/linux/man-pages/man3/pthread_setname_np.3.html
pthread_setname_np(pthread_self(), entry->name.c_str());
#else
pthread_setname_np(entry->name.c_str());
#endif
4,int num
这个 num 好像就是简单统一一下线程的编号,例如第一个线程的 num 是 1,第二个线程的 num 是 2。
5,pid_t tid
tid 是线程的ID,通过 gettid() 函数来获取的。
6,srs_error_t err
线程任务的错误,默认是 srs_success 成功。始祖线程就是检测其他子线程的这个 err 字段,判断是不是 srs_success ,如果不是就写日志记录退出的原因等信息。
SrsThreadEntry 的 start() 函数指针 跟 arg 是一个重点。
srs_error_t (*start)(void* arg);
void* arg;
首先 arg 是 start 函数的参数,而 start() 的指向是在 SrsThreadPool::execute() 的时候被赋值的,如下:
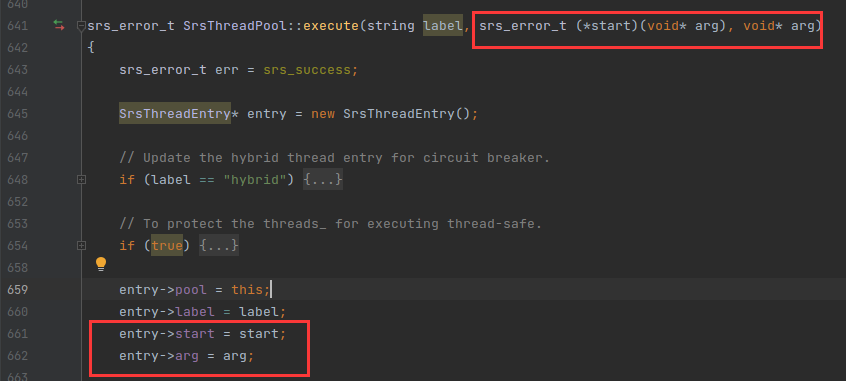
SrsThreadPool 与 SrsThreadEntry 这两个类的数据结构已经分析完毕,下面画一张图展示 SRS 从 main 开始 创建 线程的流程。如下:
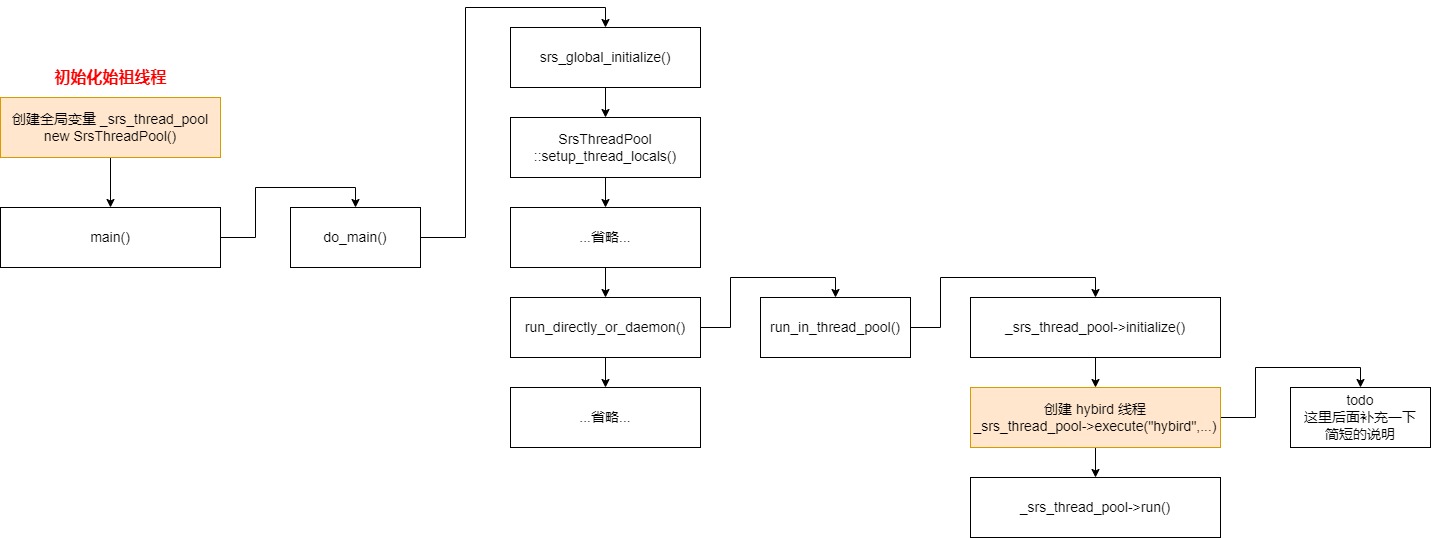
上图中中总共就 2 个线程,已经用颜色标注出来了,一个是 hybird 线程,一个是 始祖线程,始祖线程本身就是存在的,不需要 pthread_create 创建,始祖线程是在创建全局变量 _srs_thread_pool 的时候在构造函数里面进行初始化的,如下:

虽然 SRS 的线程池设计做好了,我觉得至少完成了 80%,后面改动应该不会太大。虽然他做好了,但是并没有在项目里面完全用上这个设计,可以看到,除开 SRT 模块的线程,一共就 2 个线程,就是 primordial 与 hybird 线程。
理想状态下,我觉得应该是 RTMP,RTSP,WebRTC 等等 各个模块有各自的线程。
